Analysis-Ready, Cloud-Optimised (ARCO) formats, such as Zarr or Apache Parquet, are designed to facilitate scalable and efficient access to large data sets. These formats are said to be “analysis-ready”, as they organize data into manageable chunks indexed in embedded metadata, making them ideal for intensive data processing (i.e. parallel or distributed processing), such as big data or data science.
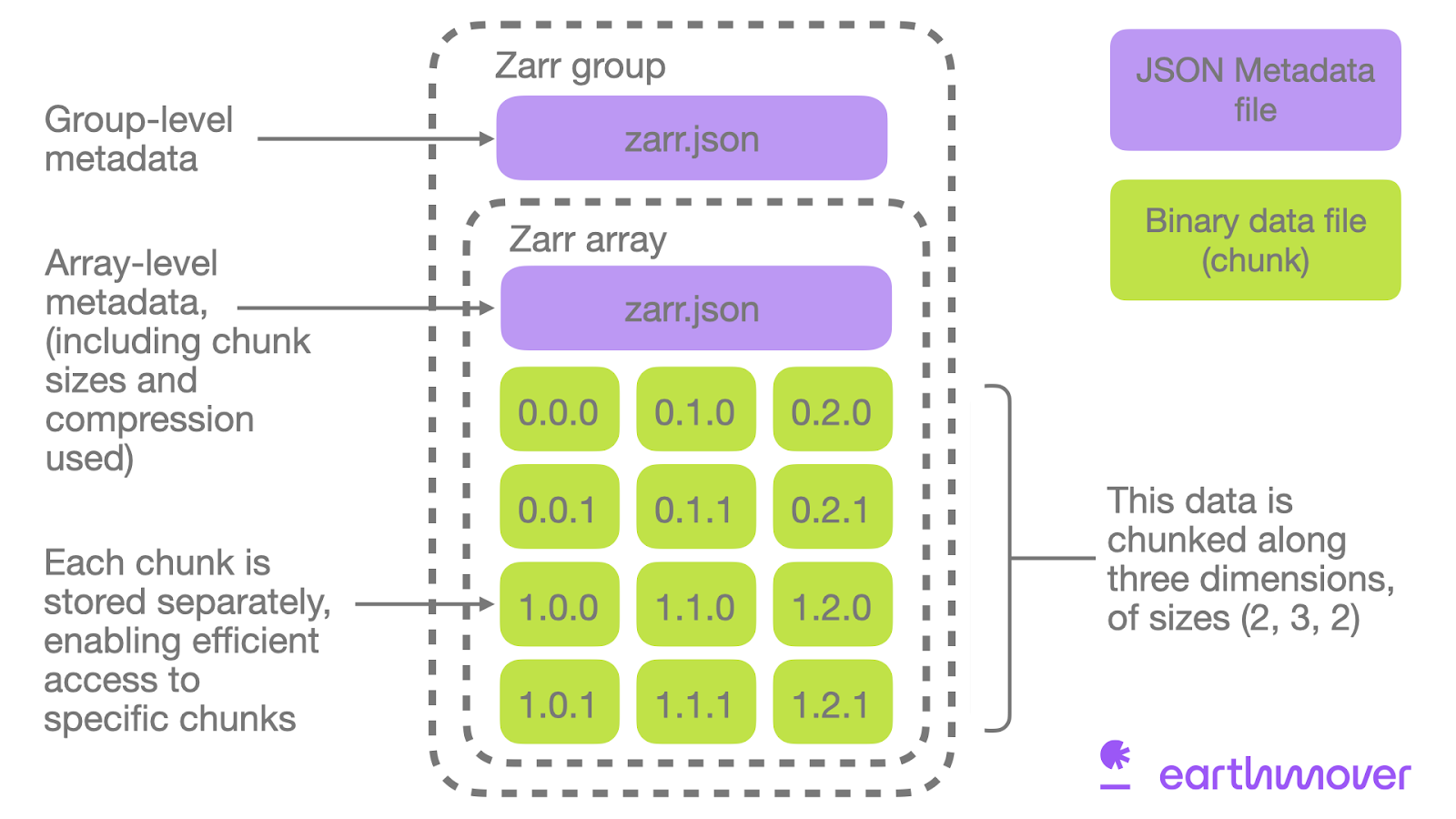
Figure 1:Zarr structure
They are said to be “cloud-optimised”, as they are compatible with HTTP range requests, i.e. the chunks and metadata are organized in such a way that the chunks of interest can be accessed without downloading the entire file. This design provides a serverless subsetting service and greatly simplifies use. For example, a multidimensional dataset can be loaded in a single line using tools such as xarray.open_dataset(“s3://.../file.zarr”). The relevant chunks will be downloaded only when a compute is performed.
Extensions to these formats exist to manage geospatial data (e.g. GeoZarr, GeoParquet). It provides simplified integration with tools such as QGIS desktop or GDAL, ensuring interoperability between desktop applications and cloud-native platforms.
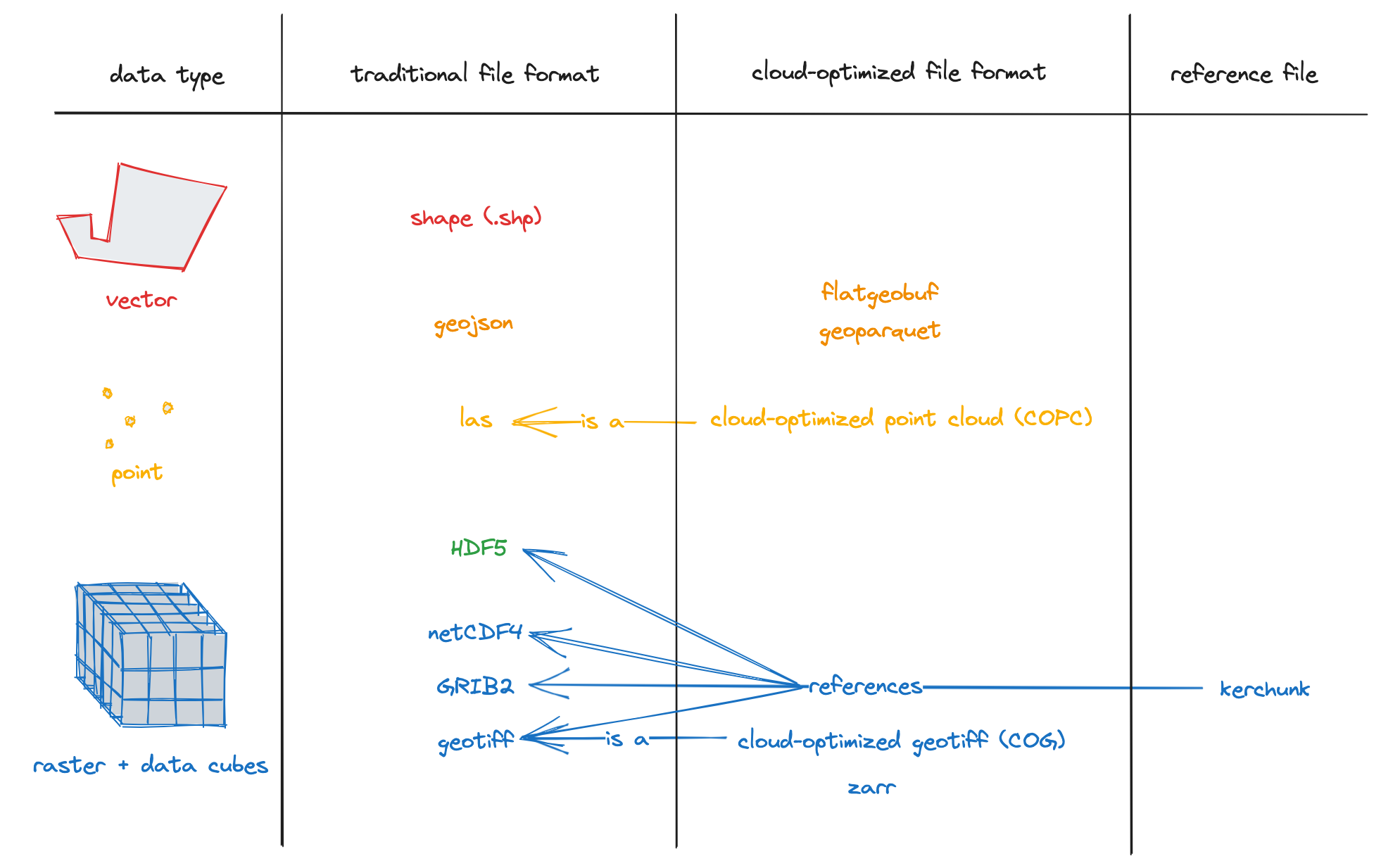
Figure 2:Cloud-Optimised Geospatial Formats
FAIR-EASE promotes the use of these formats to speed up the analysis of a subset of data, but also to improve the performance of standardised services (e.g. OGC standards) implemented by data providers. See Lobelia blog[7] for more information.
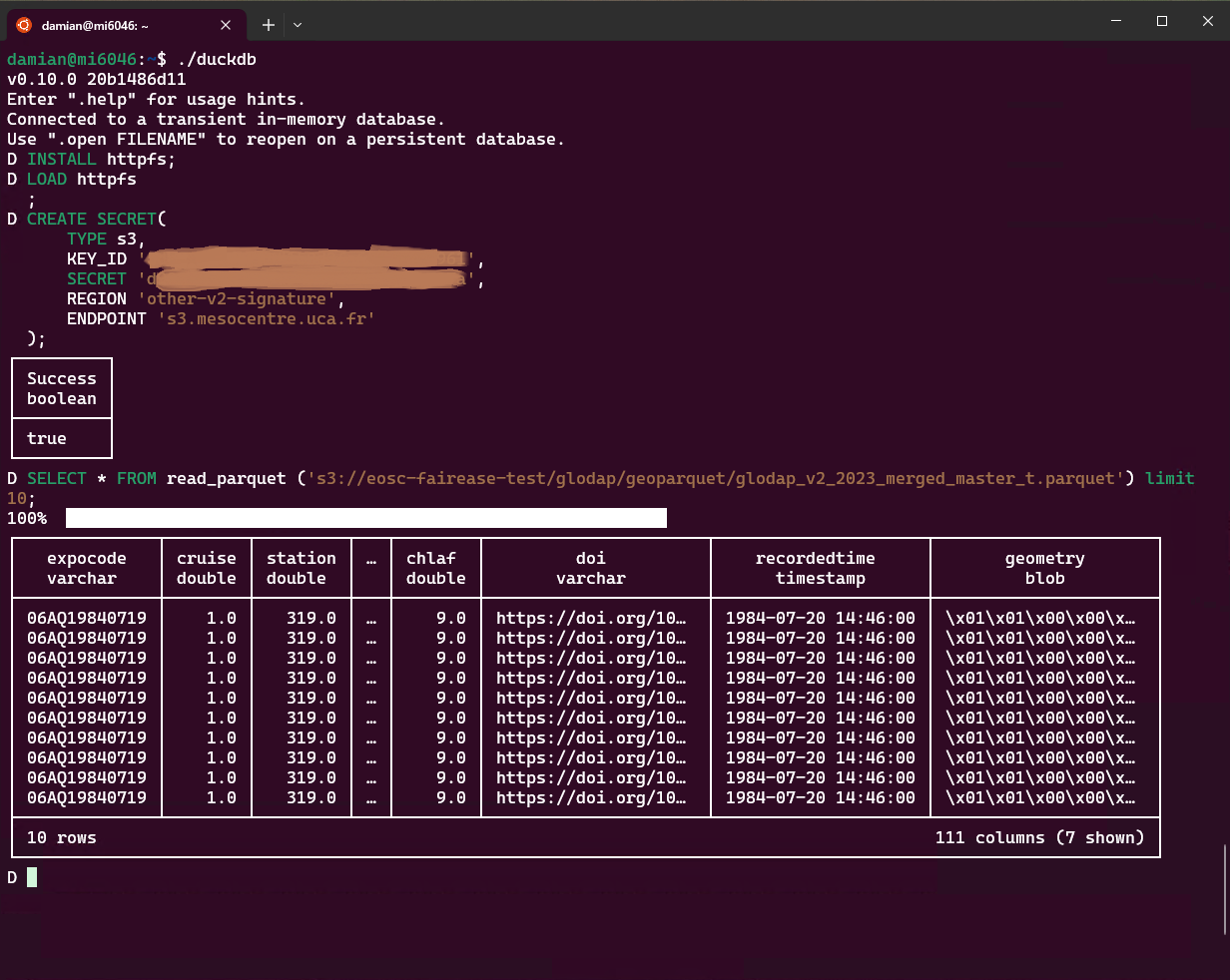
Figure 3:Querying a parquet file in an remote object store using DuckDB (https://duckdb.org)